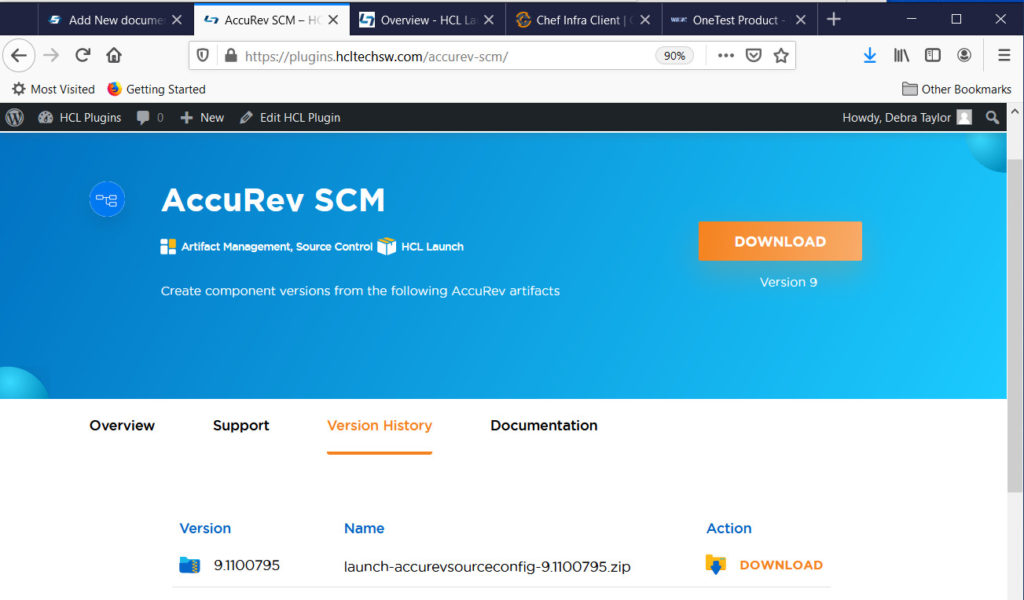
HCL AppScan Enterprise (ASE) (appscanPlugin)
| Name | Type | Required | Description |
|---|---|---|---|
| url | String | true | The URL of AppScan including the port number. For example: https://mydomain.com:9000. |
| username | String | true | The user name to use to authenticate with the AppScan server. |
| password | Secure | true | The password to authenticate with the Appscan server. |
| isScheduledEvent | Boolean | false | Check the box to run the intergration as Scheduled Event. |
| getIssueLevelData | Boolean | false | Check the box to get issue level data. |
| applications | Multiline | false | Newline seprated list of application names. If kept empty all applications will be synced. |
| workflowId | String | false | The value stream that this metric is associated. |
HCL AppScan on Cloud (ASoC) (asocPlugin)
| Name | Type | Required | Description |
|---|---|---|---|
| asocUrl | String | true | The base URL of the Application Security on Cloud server. For example: https://cloud.appscan.com/. |
| keyId | String | true | To authenticate the Application Security On Cloud , You must need to provide keyId |
| keySecret | Secure | true | To authenticate the Application Security On Cloud , You must need to provide keySecret |
| application | String | false | Application name in ASoC |
| isScheduledEvent | Boolean | false | Check the box to run the integration as a Scheduled Event. |
| policies | Array | false | Comma separated list of Policy names in ASoC – for example: OWASP Top 10 Mobile 2016, International Standard – ISO 27002 |
| workflowId | String | false | The value stream that this metric is associated. |
| proxyServer | String | false | The URL of the proxy server including the port number |
| proxyUsername | String | false | The user name used to authenticate with the proxy server |
| proxyPassword | Secure | false | The password used to authenticate with the proxy server |
Black Duck (blackDuckPlugin)
| Name | Type | Required | Description |
|---|---|---|---|
| blackDuckUrl | String | true | The base URL of the Black Duck server. |
| accessToken | Secure | false | The access token to authenticate with the Black Duck server. You can use either this property or the password to authenticate with the server. |
| ucvAccessKey | Secure | false | The user access key used to authenticate with this server (Prior to version 3.0.0). |
SonarQube (sonarqubePlugin)
| Name | Type | Required | Description |
|---|---|---|---|
| url | String | true | The base URL of SonarQube server. Include the port number.For example: https://mydomain.com:9000. |
| authToken | Secure | true | The authentication token used to request additional data. |
| velocityAccessKey | Secure | false | User access key for authentication with this server (Prior to version 3.0.0). |
Digital.ai Agility (ucv-ext-agility)
| Name | Type | Required | Description |
|---|---|---|---|
| serverUrl | String | true | The URL of the agility server. |
| userId | String | true | The user name used to authenticate with Digital.ai Agility server. |
| accessToken | Secure | false | The access token used to authenticate with the Digital.ai Agility server. Either the Password or AccessToken property must contain a value. Do not specify a value for both at the same time. |
| password | Secure | false | The password used to authenticate with the Digital.ai Agility server. Either the Password or AccessToken property must contain a value. Do not specify a value for both at the same time. |
| projects | Array | true | A comma separated list of Digital.ai Agility projects from which work items are imported. |
| proxyServer | String | false | The URL of the proxy server including the port number. The URL protocol can be http or https. |
| proxyUsername | String | false | The user name used to authenticate with the proxy server. |
| proxyPassword | Secure | false | The password used to authenticate with the proxy server. |
MicroFocus ALM Octance (ucv-ext-alm-octane)
| Name | Type | Required | Description |
|---|---|---|---|
| serverUrl | String | true | The URL of the ALM Octane server. |
| userName | String | false | The user name to authenticate with the ALM Octane server. Use either Username/Password or Client ID/Secret for authentication. |
| password | Secure | false | The password used to authenticate with the ALM Octane server. |
| clientId | String | false | The client id to authenticate with the ALM Octane server. Use either Username/Password or Client ID/Secret for authentication. |
| clientSecret | Secure | false | The client secret used to authenticate with the ALM Octane server. |
| version | String | true | The version of MicroFocus ALM Octane server. |
| sharedspaceId | String | true | The UID of the Shared Space. |
| workspaceId | Array | true | a list of WorkSpace Id separated by commas. |
| ucvAccessKey | Secure | false | User access key for authentication with this server (Prior to version 2.4.0). |
Azure DevOps (ucv-ext-azure)
| Name | Type | Required | Description |
|---|---|---|---|
| baseUrl | String | true | The URL of the Azure DevOps server. |
| username | String | true | The user name to authenticate with the Azure DevOps server. |
| password | Secure | false | The password used to authenticate with the Azure server. Use either this or an access token. |
| accessToken | Secure | false | The access token to authenticate with the Azure DevOps server. You can use either this property or the Password property to authenticate with the server. |
| organization | String | true | The name of the Azure organization in which the specified project exists. |
| project | String | true | The name of the Azure DevOps project from which to pull data. |
| repositories | Array | false | A comma separated list of repositories from which to import pull requests, commits, and build data. |
| branchName | String | false | The branch to pull commits from. |
| otherBranches | Array | false | A comma separated list of additional branches to collect commits from besides the main one, leave blank if not needed. |
| proxyServer | String | false | The URL of the proxy server including the port number. |
| proxyUsername | String | false | The user name used to authenticate with the proxy server. |
| proxyPassword | Secure | false | The password used to authenticate with the proxy server. |
| apiLimits | String | false | Maximum number of Azure Devops REST API calls that will be made by the plugin in a single execution. Making too many call in a short duration might result in a connection timeout at Azure Devops server. |
| tags | Array | false | Comma separated list of tags for pushing pipeline runs as build to this server. If kept empty all the pipeline runs will be pushed as builds. |
Bitbucket Cloud (ucv-ext-bitbucket-cloud)
| Name | Type | Required | Description |
|---|---|---|---|
| username | String | true | The user name used to authenticate with the Bitbucket cloud instance.You can find it here https://bitbucket.org/account/settings/ |
| password | Secure | true | The app password used to authenticate with the Bitbucket cloud instance.You can create one here https://bitbucket.org/account/settings/app-passwords/ |
| projectKey | String | true | The project key of the repository. |
| repositoryName | Array | true | The comma separated name of the repositories. |
| branchName | String | false | The branch to pull changes from. |
| otherBranches | Array | false | The name of additional branches to collect commits from besides the main one, leave blank if not needed. |
| proxyServer | String | false | The URL of the proxy server including the port number |
| proxyUsername | String | false | The user name used to authenticate with the proxy server |
| proxyPassword | Secure | false | The password used to authenticate with the proxy server |
| apiLimits | String | false | Maximum API calls that the plugin will make in a single run. |
BitBucket Server (ucv-ext-bitbucket-server)
| Name | Type | Required | Description |
|---|---|---|---|
| baseApiUrl | String | true | The base URL of the API. |
| username | String | false | The user name used to authenticate with the BitBucket server. |
| password | Secure | false | The password associated with the user name to authenticate with the BitBucket server. |
| signature_method | String | false | The name of the signature method for oauth authentication. |
| consumer_key | String | false | The consumer key for Oauth authentication. |
| consumer_secret | Secure | false | The consumer secret for Oauth authentication. |
| access_token | String | false | The access token for Oauth authentication. |
| access_token_secret | Secure | false | The access token secret for Oauth authentication. |
| projectKey | String | true | The repository project key. |
| repositoryName | Array | true | Add list of comma seprated names of the repository. |
| branchName | String | false | The name of the branch to pull changes from. |
| otherBranches | Array | false | The name of additional branches to collect commits from besides the main one, leave blank if not needed. Regular expression is enabled (Example: PLUGINS-*,*) |
Bottleneck Detection (ucv-ext-bottleneck-detection)
| Name | Type | Required | Description |
|---|---|---|---|
| ucvKey | Secure | true | UCV User Access key |
CircleCI (ucv-ext-circleci)
| Name | Type | Required | Description |
|---|---|---|---|
| apiUrl | String | true | API URL of CircleCI. |
| projectType | String | true | The Version Control System that is used, for example: github, bitbucket. |
| orgName | String | true | The username or organization name in the version control system. |
| repositories | Array | true | A comma separated list of repositories from which to import pull requests, commits, and build data. |
| accessToken | Secure | true | The access token to authenticate with CircleCI. |
| branch | String | false | The branch for which build data is to be synced. If nothing is specified, the default_branch of the project will be used. |
| proxyServer | String | false | The URL of the proxy server including the port number. The URL protocol can be http or https. |
| proxyUsername | String | false | The user name used to authenticate with the proxy server. |
| proxyPassword | Secure | false | The password used to authenticate with the proxy server. |
HCL Compass (ucv-ext-compass)
| Name | Type | Required | Description |
|---|---|---|---|
| serverUrl | String | true | The URL of the Compass server. |
| userName | String | true | The user name to authenticate with the Compass server. |
| password | Secure | false | The password used to authenticate with the Compass server. |
| repo | String | true | The repository name of the Compass project. |
| db | String | true | The name of the Compass database where the data to be pulled is located. |
| fieldMapping | Multiline | true | Map Compass fields to Accelerate as a JSON Object. |
| timezone | Dropdown | true | The timezone offset from the Coordinated Universal Time (UTC). For example, if the timezone is Asia/Kolkata select UTC+05:30. |
| since | String | false | Issues or work items are imported for the specified number of months when the plug-in runs for the first time. |
GitHub Dependabot (ucv-ext-dependabot)
| Name | Type | Required | Description |
|---|---|---|---|
| graphqlApiUrl | String | true | For Enterprise edition , replace it with Enterprise GraphQL endpoint. For example: http(s)://[hostname]/api/graphql |
| personal_access_token | Secure | true | Personal Access Token to authenticate with the Github server. Required unless OAuth information is provided. |
| filter_repos | Array | false | Add repository names as comma separated for specific repository data.By default it will scan all repositories. |
IBM Engineering Workflow Management (EWM) (ucv-ext-ewm)
| Name | Type | Required | Description |
|---|---|---|---|
| serverUrl | String | true | The URL of the EWM repository. For example: https://server.com/ccm |
| projects | Array | true | Comma separated list of projects from which work items are to be extracted. |
| userId | String | true | The user ID used to authenicate with the repository. |
| password | Secure | true | The password used to authenicate with the repository. |
| since | String | false | Issues since how many months are to be imported when the plugin runs for the first time, default is 12 months |
| ucvAccessKey | Secure | false | User access key for authentication with this server (Prior to version 2.4.0). |
| proxyServer | String | false | The URL of the proxy server including the port number. |
| proxyUsername | String | false | The Username used to authenticate with the proxy server. |
| proxyPassword | Secure | false | The Password used to authenticate with the proxy server. |
Fortify SSC (ucv-ext-fortify-ssc)
| Name | Type | Required | Description |
|---|---|---|---|
| baseUrl | String | true | The base URL of Fortify SSC server. |
| token | Secure | true | API key for authentication. |
| projectNames | Array | false | Comma separated list of project names to sync data. If kept empty, syncs all projects data. |
| workflowId | String | false | The value stream that this metric is associated. |
GitHub (ucv-ext-github)
| Name | Type | Required | Description |
|---|---|---|---|
| apiUrl | String | true | The URL to the REST API v3 for the GitHub instance. API URL for GitHub free edition: https://api.github.com |
| owner | String | true | The owner name of the GitHub repository |
| token | Secure | true | The Personal Access Token used to authenticate with Github repositories |
| repositories | Array | true | List of Github Repository names (separated by comma). Regular expression is enabled (Example: ucv-ext-*, repo-name*, *repo*-abc) |
| branch | String | false | Branch to pull commits from Github repository |
| otherBranches | Array | false | List of Branches (separated by comma) to collect commits from besides the main one. Leave blank if not needed |
| proxyServer | String | false | The URL of the proxy server including the port number |
| proxyUsername | String | false | The user name used to authenticate with the proxy server |
| proxyPassword | Secure | false | The password used to authenticate with the proxy server |
GitLab (ucv-ext-gitlab)
| Name | Type | Required | Description |
|---|---|---|---|
| baseUrl | String | true | The URL of the GitLab server. |
| private_token | Secure | true | The GitLab server access token. For more information, see the GitLab documentation at https://gitlab.com/profile/personal_access_tokens. |
| projectNames | Array | false | You can import the source data by providing a list of GitLab Project Names, which can include regular expressions for pattern matching. For instance, you can use wildcards such as * to match any character sequence, such as sample* to match project names that start with sample. Example: sample, sample1, etc. |
| projectIds | Array | false | To import the source data, you need to provide a list of GitLab Project IDs. Please note that you must provide at least one of either Project Names or Project IDs, and can provide both if needed. |
| branchName | String | false | GitLab repositories branch, The branch to pull commits from. |
| otherBranches | Array | false | The name of additional branches to collect commits from besides the main one, leave blank if not needed. |
| fieldMapping | Array | false | Map GitLab label for Priorty to this server. The priorty field label must be a key vaule pair connected by “:” or “-“. Example: If Gitlab Label for priorty is priortyKey:High, then pass priortyKey here. |
| proxyServer | String | false | The URL of the proxy server including the port number |
| proxyUsername | String | false | The user name used to authenticate with the proxy server |
| proxyPassword | Secure | false | The password used to authenticate with the proxy server |
HCL Launch (ucv-ext-launch)
| Name | Type | Required | Description |
|---|---|---|---|
| baseUrl | String | true | HCL Launch server url |
| launchToken | Secure | true | Token to authenticate against HCL Launch |
LeanKit (ucv-ext-leankit)
| Name | Type | Required | Description |
|---|---|---|---|
| baseUrl | String | true | The URL of the LeanKit server. |
| private_token | Secure | true | The LeanKit server access token. |
| boardIds | Array | false | A list of Leankit Board IDs separated by commas. Example: 1501106201,9501056040 |
| ucvAccessKey | Secure | false | User access key for authentication with this server (Prior to version 2.4.0). |
Milestone Risk Prediction (ucv-ext-milestone-risk-prediction)
| Name | Type | Required | Description |
|---|---|---|---|
| ELASTIC_URL | String | true | Elasticsearch URL |
HCL OneTest API (ucv-ext-onetest-api)
| Name | Type | Required | Description |
|---|---|---|---|
| oneTestDBUrl | String | true | The hostname of the HCL OneTest Database. |
| oneTestDB | String | true | The name of HCL OneTest Database. |
| oneTestDBUsername | String | true | The user name to authenticate with the HCL OneTest Database. |
| oneTestDBPassword | Secure | true | The password to authenticate with the HCL OneTest Database. |
| workflowId | String | false | The value stream that this metric is associated. |
HCL OneTest Server (ucv-ext-onetest-server)
| Name | Type | Required | Description |
|---|---|---|---|
| oneTestUrl | String | true | The base URL of the HCL OneTest Server. For example: https://tp-cicd2.nonprod.hclpnp.com. |
| oneTestRefreshToken | Secure | true | The offline user token created in the HCL OneTest user interface by clicking the Create Token button. |
| buildRegExp | String | false | A regular expression pattern to match a build ID on a test execution label. For example: ([A-Z]+-[0-9]+). |
| workflowId | String | false | The value stream that this metric is associated. |
HCL OneTest Service Virtualization (ucv-ext-onetest-sv)
| Name | Type | Required | Description |
|---|---|---|---|
| oneTestUrl | String | true | The API URL of the HCL OneTest Kairos Database. |
| workflowId | String | false | The value stream that this metric is associated. |
Rally (ucv-ext-rally)
| Name | Type | Required | Description |
|---|---|---|---|
| baseUrl | String | true | The URL of the Rally server. The default is https://rally1.rallydev.com. |
| username | String | false | The user name used to authenticate with the Rally server. Specify either the username and password properties or the apiKey property. |
| password | Secure | false | The password used to authenticate with the Rally server. Specify either the username and password properties or the apiKey property. |
| apiKey | Secure | false | The API token used to authenticate with the Rally server. You must specify a value for either this property or the username and password properties. |
| workspace | String | false | The name of the Rally workspace to use on request. This property is required if you are not using a default workspace. |
| projects | Array | false | Comma separated list of Rally project names to import data. |
| proxyServer | String | false | The URL of the proxy server including the port number Ex-https://ProxyUrl:Port/ |
| proxyUsername | String | false | The user name used to authenticate with the proxy server |
| proxyPassword | Secure | false | The password used to authenticate with the proxy server |
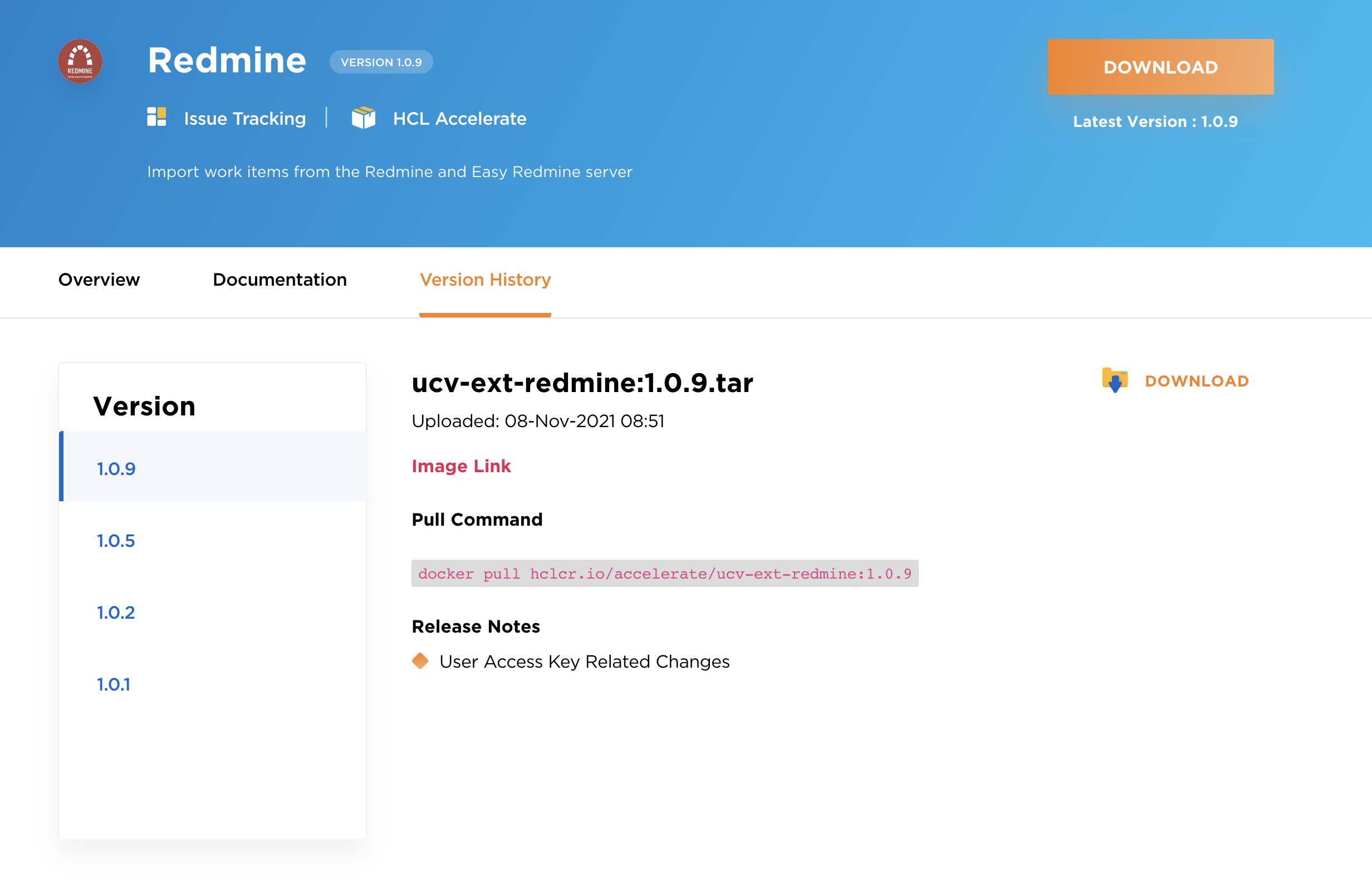
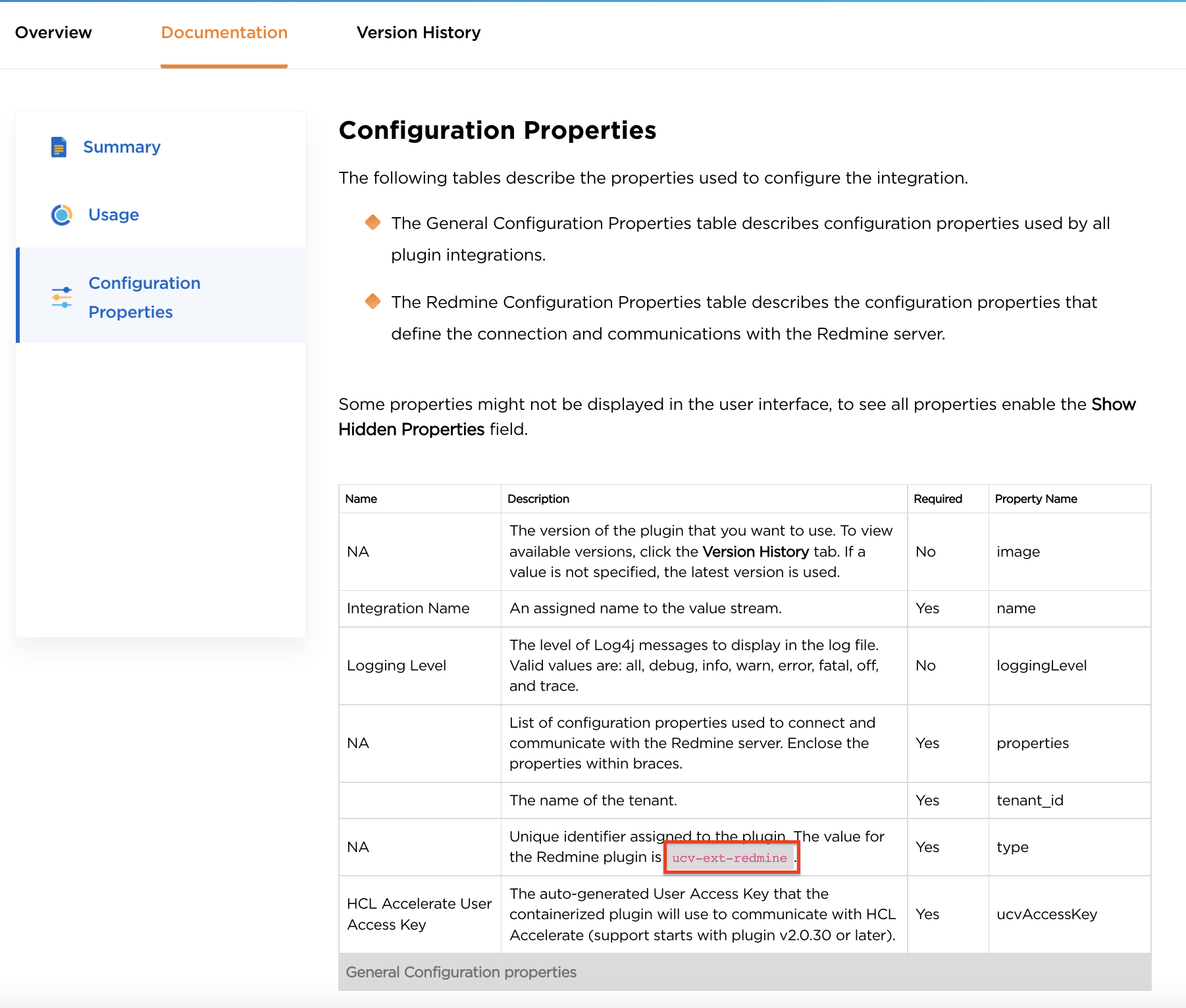
Redmine (ucv-ext-redmine)
| Name | Type | Required | Description |
|---|---|---|---|
| baseUrl | String | true | The URL of the Redmine server. |
| private_token | Secure | true | The Redmine server access token. For more information, see at https://www.redmine.org/boards/2/topics/54459 |
| projectIds | Array | true | Comma separated list of Redmine Project IDs to import the source data. |
| proxyServer | String | false | The URL of the proxy server including the port number |
| proxyUsername | String | false | The user name used to authenticate with the proxy server |
| proxyPassword | Secure | false | The password used to authenticate with the proxy server |
Rational Test Automation Server (ucv-ext-rtas)
| Name | Type | Required | Description |
|---|---|---|---|
| rtasUrl | String | true | The base URL of the Rational Test Automation Server. E.G. https://tp-cicd2.nonprod.hclpnp.com. |
| rtasOfflineToken | Secure | true | The offline user token created in the RTAS UI by clicking the Create Token button. |
| buildRegExp | String | false | A regular expression pattern that will match a build ID on a test execution label. For example: ([A-Z]+-[0-9]+). |
| logLevel | String | false | The level of Log4j messages to display on the console. Valid values are: all, debug, info, warn, error, fatal, off, and trace. |
| ucvAccessKey | Secure | false | The user access key to authenticate with this server (Prior to version 3.0.0). |
SAP ChaRM (ucv-ext-sap-charm)
| Name | Type | Required | Description |
|---|---|---|---|
| sapUrl | String | true | The base URL of the SAP ES1 server. |
| sapUrlNine | String | false | The base URL of the SAP N09 server if ATC Checks are required else leave it empty. |
| sapUser | String | true | The SAP user name . |
| sapPassword | Secure | true | The SAP user password |
| sapProject | String | false | The SAP project name. |
| sapCustomFieldMapping | Multiline | true | Map Jira custom fields for storing SAP data in Jira, for example: {“sap_user”: “SAP User V2″,”sap_charm_id”: “SAP CharmID V2″,”customizing_transport_id_count”:”Customizing Transport ID Count”,”workbench_transport_id_count”:”Workbench Transport ID Count”,sap_cycle_id”: “SAP CycleID V2″,”sap_project”: “SAP Project V2″,”sap_landscape_id”: “SAP Landscape ID V2”} |
| baseUrl | String | true | The base URL of the Jira server. Example: https://jira.dev.com |
| jiraProjects | Array | true | A list of Jira Project Keys separated by commas. Example: PROJ1, PROJ2 |
| jiraJql | String | false | JQL Query has higher priority than Project Keys . If JQL Query is added , Project Keys will not work . |
| username | String | false | Username to authenticate with the Jira server. Required unless OAuth information is provided. |
| password | Secure | false | Password/Personal Access Token to authenticate with the Jira server. Required unless OAuth information is provided. |
| consumer_key | String | false | The Consumer Key for OAuth authentication. If supplied, Username and Password will be ignored. |
| consumer_secret | Secure | false | The Consumer Secret for OAuth authentication. If supplied, Username and Password will be ignored. |
| access_token | String | false | The Access Token for OAuth authentication. If supplied, Username and Password will be ignored. |
| access_token_secret | Secure | false | The Access Token Secret for OAuth authentication. If supplied, Username and Password will be ignored. |
| proxyServer | String | false | The URL of the proxy server including the port number. |
| proxyUsername | String | false | The Username used to authenticate with the proxy server. |
| proxyPassword | Secure | false | The Password used to authenticate with the proxy server. |
| fieldMapping | Multiline | false | Map Jira fields to the fields expected by this server as a Name Value pair, for example, “Epic Link”: “Epic field in Jira”, “Sprint”: “Sprint field in Jira”, “Story Points”: “Story field in Jira” . |
SAP ITSM (ucv-ext-sapitsm)
| Name | Type | Required | Description |
|---|---|---|---|
| sapUrl | String | true | The base URL of the SAP server. Example: https://sap.example.com |
| sapUser | String | true | Provide the SAP user ID. Example: 22211001 |
| sapPassword | Secure | true | Provide the SAP User password . |
| ucvAccessKey | Secure | false | User access key for authentication with this server. |
ServiceNow (ucv-ext-servicenow)
| Name | Type | Required | Description |
|---|---|---|---|
| baseUrl | String | true | The URL of the ServiceNow Server. |
| username | String | true | The user name used to authenticate with the ServiceNow server. |
| accessToken | Secure | false | The access token used to authenticate with the ServiceNow server. You can use either this property or the Password property to authenticate with the server. |
| password | Secure | false | The password used to authenticate with the ServiceNow server. You can use either this property or the Access Token property to authenticate with the server. |
| proxyServer | String | false | The URL of the proxy server including the port number |
| proxyUsername | String | false | The user name used to authenticate with the proxy server |
| proxyPassword | Secure | false | The password used to authenticate with the proxy server |
Snyk (ucv-ext-snyk)
| Name | Type | Required | Description |
|---|---|---|---|
| personal_access_token | Secure | true | Personal Access Token to authenticate with the Github server. Required unless OAuth information is provided. |
| organisation_ids | Multiline | true | Add organisation IDs as line separated to import data. |
| project_names | Multiline | false | Add project names as line separated for specific project data.By default it will scan all projects. |
UrbanCode Deploy ( External ) (ucv-ext-ucd)
| Name | Type | Required | Description |
|---|---|---|---|
| baseUrl | String | true | UrbanCode Deploy server url |
| deployToken | Secure | true | Token to authenticate against UrbanCode Deploy |
VersionVault Express (ucv-ext-vv-express)
| Name | Type | Required | Description |
|---|---|---|---|
| isScheduledEvent | Boolean | false | Check the box to run the integration as a Scheduled Event. |
| url | String | false | The URL of the VersionVault Express server including the port number. |
| projects | Array | false | Comma-separated list of project names. |
| username | String | false | The user name to use to authenticate with the VersionVault Express server. |
| password | Secure | false | The password to authenticate with the VersionVault Express server. |
WhiteSource (ucv-ext-whitesource)
| Name | Type | Required | Description |
|---|---|---|---|
| wsUrl | String | true | The base URL of the WhiteSource API. |
| userKey | Secure | true | UserKey for authentication with WhiteSource. URL to get a UserKey for WhiteSource: https://saas.whitesourcesoftware.com/Wss/WSS.html#!userProfile |
| productToken | Multiline | true | Product token for authentication with WhiteSource. URL to get a Product token for WhiteSource: https://saas.whitesourcesoftware.com/Wss/WSS.html#!userProfile |
| projectName | Multiline | false | Provide project names as line separated |
| fieldMapping | Multiline | false | Map whitesource fields to Accelerate as a JSON Object. Mapping – {“application.name”: “image.name”, “application.externalId”: “image.id”, “buildUrl”: “image.buildUrl”, “environment”:”image.environment”} |
| ucvAccessKey | Secure | false | User access key for authentication with this server (Prior to version 3.0.0). |
 ) and select Upgrade.
) and select Upgrade.